
이어드림스쿨4기 과정을 수강하면서 1차 모의 대회로 진행된 대출자 채무 불이행 여부 예측 모델을 개발한 과정입니다.
전처리(Pre-Processing)
우선 개인적으로 머신러닝 같은 경우에는 모델이 채무불이행 여부를 잘 예측할 수 있게 데이터의 특징을 잘 잡아주는 것이 중요하다고 생각합니다. 그래서 데이콘이나 캐글을 보면 파생변수 생성 또는 log 변한 등으로 모델이 채무불이행 여부를 예측하는 데 있어 도움을 준다고 판단했는데요. 이번 데이터 같은 경우에는 금융과 관련된 데이터 였지만... 저는 금융과 관련한 지식과는 거리가 먼 사람이라 최대한 search 해보거나 유사한 대회를 찾아봤던 거 같네요. 😀
- 파생변수 생성
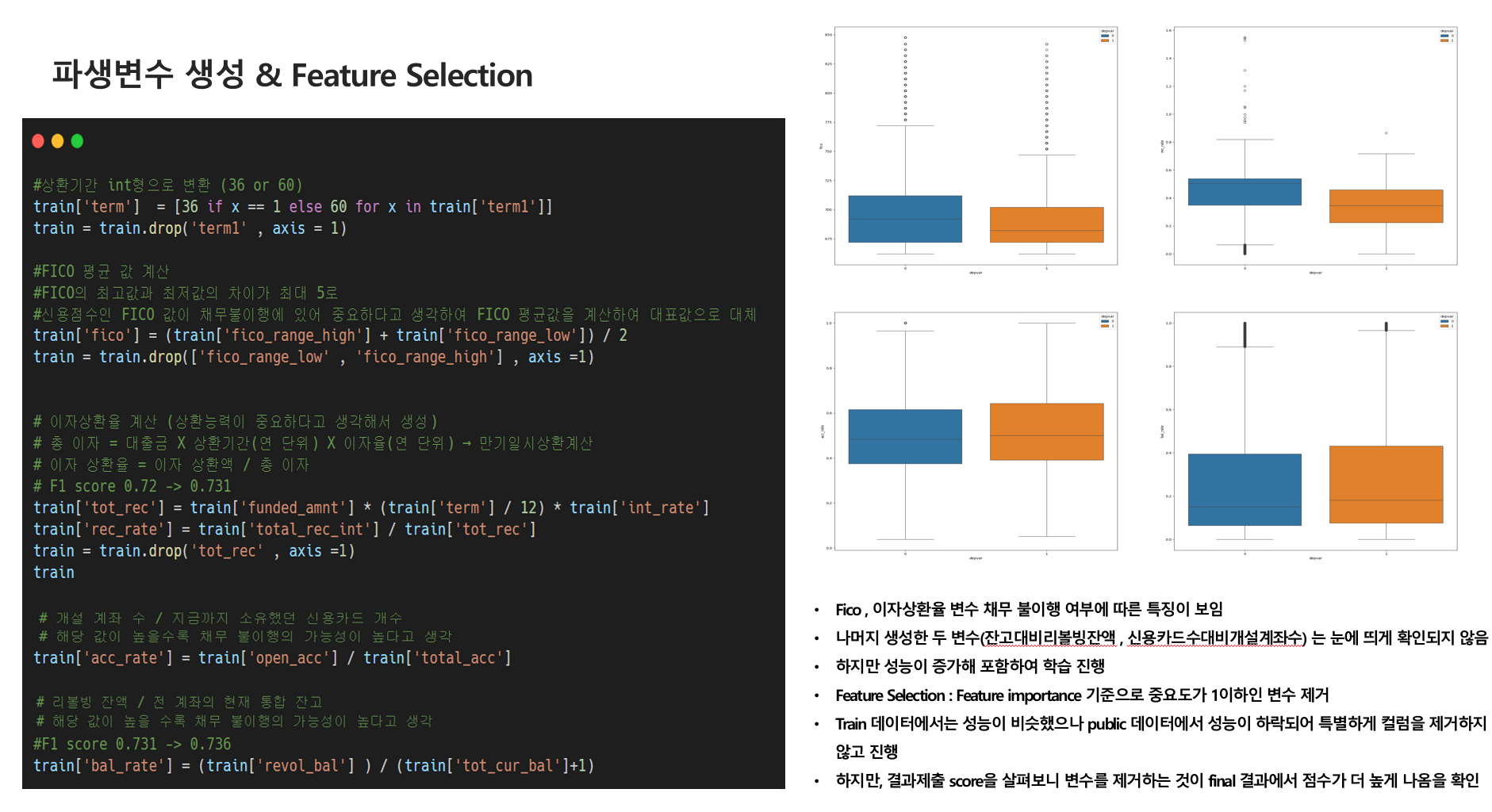
- feature 별로 하나씩 시각화를 진행했을 때 데이터의 특징들이 잘 보이지 않았습니다.
- 그래서 이렇게 생성하면 도움이 되지 않을까? 라는 추측들로 생성했습니다.
- 이후 BoxPlot으로 시각화를 통해서 생성된 변수가 유의미한 변수가 될 수 있을지 확인했네요!
#FICO 평균 값 계산
#신용점수인 FICO 값이 채무 불이행여부에 있어 중요하다고 생각
#FICO 평균값을 계산하여 두 컬럼을 대표하는 값으로 생성
train['fico'] = (train['fico_range_high'] + train['fico_range_low']) / 2
train = train.drop(['fico_range_low' , 'fico_range_high'] , axis =1)
#이자상환율계산(상환능력이 중요하다고 생각해서 생성)
#총이자 = 대출금 X 상환기간(연 단위) X 이자율(연 단위) → 만기일시상환계산
#이자상환율 = 이자상환액 / 총 이자 변수 생성
train['tot_rec'] = train['funded_amnt'] * (train['term'] / 12) * train['int_rate']
train['rec_rate'] = train['total_rec_int'] / train['tot_rec']
#train['rec_fund'] = train['tot_rec'] / train['funded_amnt']
train = train.drop('tot_rec' , axis =1)
#개설 계좌 수 / 지금까지 소유했던 신용카드개수
train['acc_rate'] = train['open_acc'] / train['total_acc']
#리볼빙 잔액 / 전 계좌의 현재 통합 잔고
train['bal_rate'] = (train['revol_bal'] ) / (train['tot_cur_bal']+1)
train
- Feature Selection (변수선택)
- data가 75 feature가 되기에 처음에는 조금 막막했습니다.
- 지금까지 이렇게 큰 feature을 다뤄본 적도 없었고, data들이 주는 정보가 있다고 생각하기에 이걸 하나씩 삭제하기도 조금 판단이 잘 서지 않았습니다.
- feature importance 기준으로 1이하인 변수를 제거를 시도해봤을 때 오히려 성능이 하락됨을 확인했고, 그래서 특별히 변수 처리를 해주지는 않았습니다.. 🥹
모델링(Modeling)
불균형 처리
- OverSampling (SMOTE)
- Cost-Sensitive Learning
- 앙상블기법(BaggingClassifier)
#class_weight 설정
from sklearn.utils.class_weight import compute_class_weight
classes = np.unique(y_train)
weights = compute_class_weight(class_weight = 'balanced' , classes = classes , y = y_train)
class_weights = dict(zip(classes , weights))
class_weights
#output
{0: 0.7414959681156734, 1: 1.535213970447131}
catboost , xgboost , LGBM 모델이 F1 score (macro) 이 높게 나옴을 확인
가장 높게 나온 catboost 모델을 사용 (random_seed = 42)
from catboost import CatBoostClassifier
from sklearn.metrics import *
cat_clf = CatBoostClassifier(random_state = 42,
class_weights = class_weights)
cat_clf.fit(x_train , y_train , verbose = 100)
cat_pred = cat_clf.predict(x_test)
f1_macro =f1_score(y_test , cat_pred, average = 'macro')
print(classification_report(y_test , cat_pred))
print(f1_macro)


Q. 멘토님께 질문
해당 대회를 진행하면서 Feature을 Selection 하는 것에 어려움을 많이 느꼈는데, 이렇게 Feature들이 많을경우 가장 먼저 하시는건 무엇인지 그리고 Feature을 selection하는 팁이 있는지 여쭤보았습니다.
해주신 답변은 regression에서는 모르겠지만, 현재 과제와 같은 classification 과제같은 경우에는 feature의 수가 증가한다고 해서 그게 문제가 되거나 하는 경험이 많지 않았다고 하셨습니다. feature을 selection하는 것에 시간을 많이 사용하기 보다는 모델 앙상블이나 이런 과정에 더 신경을 많이 쓰는 편이고, 단일모델보다는 앙상블을 많이 시도한다고 하셨습니다.
대회를 진행하면서 궁금했던 부분인데 역시 현업분과 Q&A시간은 귀하군요..!! 다음 대회에서는 모델들을 앙상블하고 하이퍼파라미터 튜닝에 조금 더 신경쓰는 시간을 가져보고자 합니다..!! 그럼 다들 수고하셨습니다.🙇🏻♀️
