1. Abstract
이미지 페인팅 분야에서는 넓은 손실 영역, 복잡한 기하학적 구조 그리고 고해상도 이미지 처리에서 종종 한계를 드러낸다. 저자들은 이러한 한계의 주요 원인이 network와 loss function의 receptive field 의 부족이라고 지적한다.
Lama는 이러한 문제를 해결하기 위해 다음과 같은 3가지 전략을 제시한다.
- We propose an inpainting network based on recently developed fast Fourier convolutions (FFCs)
- We propose the use of the perceptual loss [20] based on a semantic segmentation network with a high receptive
field. - We introduce an aggressive strategy for training mask generation, to unlock the potential of a high receptive field of the first two components.
2. Dataset

- 목표 : 컬러 이미지의 x 의 손실된 영역을 복원하는 것
- 손실된 영역은 이진 마스크 m 으로 정의
- x⊙m 은 마스크 m을 사용하여 손실된 영역을 처리한 이미지
- : Hadamard product (원소별 곱셈, element-wise multiplication).
- 손실된 영역(m=1)은 유지되고, 나머지 영역은 제거된다.
- 예를 들어서 x = [ 258 , 128 , 64] , m = [1.0.1] 이라고 할 때 , x⊙m = [255,0,64] 이다.
- : x⊙m (손실된 이미지)와 m (마스크)를 채널 방향으로 쌓아 만든 4채널 텐서.
- stack 연산
- x⊙m : 3채널(RGB 이미지)
- m : 1채널 (MASK)
- : : 4채널 텐서([R,G,B,M])
- stack 연산
- 학습데이터는 실제이미지로 부터 얻은 (손실된 이미지, 마스크) 쌍으로 구성
# x.shape = (Batch, 3, Height, Width), m.shape = (Batch, 1, Height, Width)
stacked_tensor = torch.cat([x * m, m], dim=1) # 채널 방향으로 결합
print(stacked_tensor.shape) # (Batch, 4, Height, Width)Global Context
- 이미지 전체 또는 넓은 영역을 고려
- 객체관의 관계, 전체구조, 맥락정보를 학습
Local Context
- 이미지에서 작은 영역만을 고려
- 픽셀 또는 작은 patch에서 직접적으로 주변 정보와의 관계를 학습
3. Fast Fourier Convolution ( FFC) 의 도입
FFC는 초기레이어에서 global context를 학습하기 위해 설계된 연산자이다. 기존 convolution과는 다르게 Frequency Domain을 활용하여 이미지 전체를 처리할 수 있는 넓은 수용 영역을 제공한다.
- Local Branch : 전통적인 Convolution 방식 사용
- Global Branch : Real FFT를 활용하여 Global context 학습
3.1 Real FFT란?
- FFT는 입력 데이터를 주파수 도메인으로 변환 → 주파수 도메인은 데이터의 주파수 성분 (얼마나 빠르게 값이 변하는지) 에 따라서 데이터를 분석할 수 있는 표현방식이다.
- Real FFT는 실수값만 처리하여 연산효율을 높임
- FFT는 복소수(complex values)를 반환하지만, Real FFT는 실수(real values)로 변환된 데이터를 다룸.
- 결과적으로 FFT 스펙트럼의 절반만 사용해 효율성 증가
👀 왜 복소수인가?(Complex Numbers) → 주파수 도메인에서의 데이터는 진폭과 위상으로 표현된다.
진폭 : 신호의 강도 (얼마나 큰가?)
위상 : 신호가 시간 축에서 얼마나 이동했는가?
복소수는 다음과 같이 진폭과 위상을 효율적으로 표현한다.따라서 주파수 도메인 데이터는 실수와 허수로 표현된 복소수로 나타나게된다.
z = a + bi → a: 실수 (진폭) , b: 허수(위상) , i : 허수단위
3.2 Global Branch Flow
1. Real FFT 적용
- 입력 크기 : (H,W,C) → 공간 도메인에서 표현된 데이터.
- Real FFT 변환
- 입력 데이터를 주파수 도메인으로 변환
- 주파수 데이터는 복소수(Complex values)로 표현된다. → 복소수는 Real Part와 Imaginery Part로 구성
- 결과 텐서 크기 : (H,W/2,C) → 실수 데이터는 FFT 결과가 대칭성을 가지므로 절반만 필요
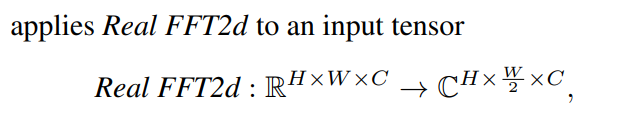
2. 실수-복소수 변환(Complex to Real)
- 주파수 도메인을 실수(real) 값으로 변환
- 복소수 데이터를 실수와 허수로 나눈 후 이 둘을 결합하여 실수 값으로 표현 → 채널 수가 두 배로 증가
- 결과 텐서 크기 : (H,W/2,2C)

3. 주파수 도메인에서 연산
- 주파수 도메인에서 Conv 수행
- 주파수 공간에서 특징 학습 및 정규화 수행
- 결과 텐서크기는 이전과 변하지 않음

4. 공간 도메인 복원
- 데이터를 다시 공간 도메인(Spatial Domain)으로 변환
- Real to Complex (실수-복소수 복원) : 실수 값으로 나뉘었던 데이터를 다시 복소수로 합침
- Inverse Real FFT(주파수 데이터를 공간 도메인으로 변환) : 다시 공간 도메인의 실수로 데이터 복원
- 결과 텐서 크기 : (H,W,C) → 입력 크기와 동일


4. Loss Function
이미지 인페인팅은 본질적으로 모호성(ambiguty)를 포함한다.
동일한 손실영역에 대해 여러가지 "가능한 복원결과"가 존재할 수 있고, 마스크가 클수록 복원이 어려워지기 때문이다.
🙆🏻♀️ 기본적인 픽셀 단위 손실 (L1, L2 손실)
모델이 예측된 결과를 원본 이미지와 정확히 일치하도록 학습시키지만, 해당 방법은 다음과 같은 문제점이 발생한다.
- 마스크 외부 정보만으로 완벽히 동일한 복원을 예측하기가 어렵다
- 결과적으로 여러 가능성을 평균화한 듯한 흐릿한(blurry) 복원 결과가 생성된다.
4.1. High Receptive Field Perceptual Loss(HRFPL)
Perceptual Loss란?
: 픽셀 단위의 차이를 측정하는 대신, 이미지 특징 공간(feature space)에서의 차이를 평가한다.
- 사전학습된 네트워크를 사용하여 이미지의 고수준(high-level) features 을 추출
- 예측된 이미지와 원본 이미지의 특징 벡터 차이를 손실로 계산
해당 방법의 장점
- 정확한 pixel matching을 요구하지 않음
- 복원된 이미지가 원본과 다양한 변형을 가질 수 있도록 허용
- 특히 전역구조(global structure)을 유지하는데 효과적
High Receptive Field Perceptual Loss(HRFPL)
: 기존의 Perceptual Loss를 개선한 방식으로, 넓은 마스크 복원에 적합하게 설계
High Receptive Field (HRF)
- 초기 layer부터 큰 수용 영역을 가진 network
- global context를 초기에 학습할 수 있어 넓은 mask 복원에 유리
- 구현 방법 : Fourier Transform 기반 layer , Dilated Convolution (확장된 커널)
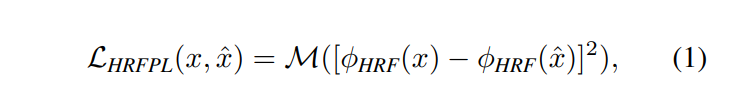
예측된 이미지와 원본 이미지의 HRF 기반 feature 차이를 평가
- [⋅−⋅]^2 : 두 특징 벡터 간의 원소별 차이를 제곱 (큰 차이에 더 큰 패널티를 부여)
- : 레이어 내부 평균 과 레이어 간 평균을 계산하여 최종 손실 값 생성
HRFPL은 전역적인 구조를 학습하도록 모델을 유도
- 원본 이미지와 복원된 이미지가 전역적으로 유사하도록 만든다.
- 정확히 동일한 복원이 아닌, 일관성이 있는 global pattern을 보존
4.2. Adverserial Loss
: Generator와 Discriminator 간의 경쟁적 학습을 통해 손실 영역을 진짜처럼 복원하도록 유도

3.2.1 Discriminator loss
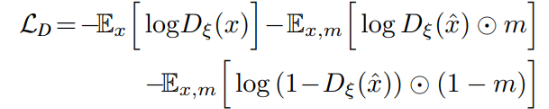

- 원본 이미지 x가 "진짜"로 판별되도록 학습
- 판별기가 1로 예측하도록 함

- 마스크 내부에서 복원된 이미지가 "가짜"로 판별되도록 학습
- 마스크 영역에서 0으로 예측하도록 함

- 마스크 외부에서 복원된 이미지가 "진짜"로 판별되도록 학습
3.2.2 Generator loss

- 생성기가 판별기에게 복원된 이미지를 "진짜"로 판별하도록 학습

- 최종 Adverserial loss는 Discriminator loss + Generator loss을 동시에 최적화함.
4.3 Final Loss

Adversarial Loss ( 복원된 이미지가 local적으로 자연스러운 디테일을 가지도록 학 )
+ High Receptive Field Perceptual Loss ( 복원된 이미지가 global 구조를 유지하도록 학습)
+ Discriminator Perceptual Loss (Feature Matching Loss, 중간 레이어에서 추출한 특징을 기반으로 디테일 개선)
+ R1 (gradient 를 규제하여 학습을 안정화)
⭐ Github Code에서 살펴보기
Generator loss
1. L1 loss (Mean Absolute Error) : 원본 이미지와 복원된 이미지 간의 픽셀 차이를 최소화
2. Perceptual Loss : VGG 기반의 특징 공간에서 원본 이미지와 복원된 이미지간의 차이를 계산
3. Adversarial Loss : 판별기를 속이도록 학습 (복원된 이미지가 진짜로 판별되도록 유도)
4. Feature Matching Loss : 중간 레이어에서 추출한 특징 벡터를 비교
Discriminator loss
1. Adversarial Loss
2. Fake-Fakes Adveserial Loss
3. Gradient Penalty (R1)
5. 구현세부사항
네트워크 구조 → ResNet 기반 구조
- 3개의 DownSampling Blocks
- 6~18개의 Residual Blocks
- 3개의 UpSampling Blocks
최적화 방법
- Adam 옵티마이저 사용.
- 고정 학습률:
- 0.001 : Inpainting Network
- 0.0001 : Discriminator Network
- Batch size : 30
하이퍼파라미터 설정 → Coordinate-Wise Beam Search 전략을 사용하여 최적
- : Adversarial Loss의 가중치.
- : HRF Perceptual Loss의 가중치.
- : Discriminator-based Perceptual Loss의 가중치.
- : Gradient Penalty의 가중치.
👀 참고자료
Introduction to image inpainting with a practical example from the e-commerce industry
Image inpainting is the task of restoring missing or damaged regions of an image using information from the surrounding pixels. Image…
medium.com
https://github.com/advimman/lama
GitHub - advimman/lama: 🦙 LaMa Image Inpainting, Resolution-robust Large Mask Inpainting with Fourier Convolutions, WACV 202
🦙 LaMa Image Inpainting, Resolution-robust Large Mask Inpainting with Fourier Convolutions, WACV 2022 - advimman/lama
github.com
'CV(컴퓨터비전)' 카테고리의 다른 글
| TTA(Test time Augmentation) (0) | 2024.11.28 |
|---|