1. Self Attention
Self Attention이란 말 그래도 자기 자신에게 수행하는 Attention 기법이다. 그렇다면 왜 이런 행위를 하는 것일까? 그 이유는 바로 문장에서 단어들의 연관성을 알기 위해서다.

위 그림을 참고하여, 만일 "The animal didn't cross the street because it was too tired"라는 문장이 있다고 하자. 여기서 'it'이 가리키는 단어는 문맥상 'animal' 임을 알 수 있고, 이 둘의 단어는 관련이 높다고 할 수 있다. 이러한 과정을 컴퓨터가 할 수 있도록 하는 것이다.
즉 , self attention은 자기자신이 Query이자 Key, Value이며 입력으로 들어온 Sequence 내에서 단어들 간의 관계를 계산하 방법(관련이 높은 단어에 더 많은 가중치) 이라고 할 수 있다.
self-attention 에서는 Query, Key, Value 3가지 변수가 존재한다. Query는 현재 단어가 어떤 정보에 주의를 기울여야하는지를 나타내고, Key는 각 단어가 어떤 정보를 가지고 있는지 나타내는지 단어의 id와 같은 역할, Value는 실제로 해당 단어에 대한 구체적인 정보를 나타낸다.
😀 쉽게 비유해보자면 다음과 같다.
만약 당신이 유튜브나 구글에서 무언가를 검색한다면, 검색 상자에 입력하는 텍스트가 Query 이다. 비디오 또는 기사 제목으로 표시되는 결과는 Key이며, 그 안의 내용은 Value 라고 할 수 있다.
2. Transformer에서의 Self-attention 작동순서

입력 : Query (q) 하나와 여러 Key-value (k,v) 쌍
출력 : Value 벡터의 가중평균 (Weighted Average)
- 각 Value의 가중치는 대응되는 Key와 Query의 Inner product로 계산한다.
단계 1. Query와 Key의 MatMul (내적)
⇒ 우선 처음에는 Query와 Key를 내적해준다. 이렇게 내적해주는 이유는 둘 사이의 유사도(연관성)을 계산하기 위해서이다. 이렇게 내적된 값을 "Attention score"라고 한다.
단계 2. Scale
⇒ 그런데 만일 Query와 Key의 차원(dimension)이 커지면 내적(Dot product) 했을 때 내부 값들의 분산이 커지게 된다. 이렇게 되면 모델의 학습이 어려움이 생길 수 있고, 이를 안정화하기 위해 Query의 차원의 루트만큼 나눠주는 scaling 작업을 하는 것이다.
더 자세히는 , 내적의 분산이 커지면 softmax를 취했을 때 분포가 logit 값이 큰 쪽으로 확률이 쏠리는 현상이 발생하고, 이는 Backpropagation시 gradient vanishing 문제를 발생시킬 수 있다. 이러한 문제를 해결하기 위해 scaling을 하여 모든 key확률이 고르게 부여되도록 한다.
여기까지지의 과정을 "Scaled Dot-Product Attention"이라고 한다.
단계 3. Mask(opt.)
⇒ 여기서 Opt. 라는 라벨의 의미와 같이 Optional한 부분이다. 입력 문장 중 word인지 아닌지 여부를 Masking 을 통해 구분하는 기능을 수행한다. 이는 word 입력이 끝난 후 padding 처리하는 것과 동일하다.
단계 4. SoftMax
⇒ scale 이후에 SoftMax layer에 통과시켜 위에서 구한 Attention Score을 최종적으로 0에서 1의 값으로 변환한다. 이렇게 하면 각 단어의 중요도에 대한 가중치를 얻을 수 있다. 이 가중치는 Query와 Key 사이의 상대적인 중요도를 나타낸다. 즉, 가중치가 높을수록 해당 단어는 문장의 의미를 이해하는데 더 큰 영향을 미친다.
5. Value 와 Dot-Product
Value와 (Query와 Key 내적에 Softmax를 취한 Attention Score) 을 내적하여 최종적으로 Self Attention의 결과를 얻게 된다.
위 과정을 수식으로 나타내면 다음과 같다.
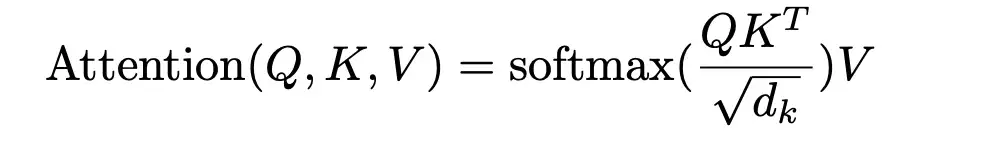
3. Positional Encoding이란 ?
RNN 구조에서는 순서대로 들어오는 입력이 자연스럽게 모델이 들어와서 순서를 고려할 수 있었으나, Transformer 매커니즘에서 문장을 한 번에 처리하자 단어간의 순서가 반영되지 않는다. 언어는 시계열데이터이기 때문에 문장에서 순서는 해석에 큰 영향을 미친다.
예를 들어 "나는 고기를 먹었다" 와 "고기는 나를 먹었다" 를 보면 고기와 나의 위치가 바꼈을 뿐인데 문장의 의미는 완전히 달라지게 된다. 이러한 순서 문제를 해결하기 위해서 ransformer 모델에서는 모델에 입력되는 입력 임베딩(Input Embedding)에 Positional Encoding이라 불리는 입력 임베딩과 같은 차원인 위치정보를 담고 있는 벡터를 더해준다.
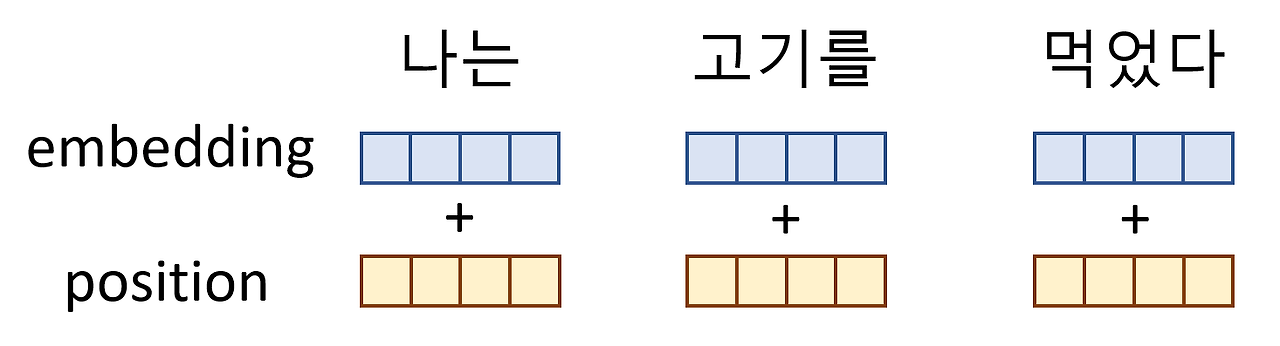
이때 positional embedding의 조건은 다음과 같다
- 모델의 효율적인 학습을 위해 스케일은 어느정도 범위 안에 있어야 한다.
- 만약, positional embedding의 스케일 범위가 너무 크면 이 자체 값의 영향력이 너무 커져 다른 값이 무시되어 학습이 되지 않을 수 있다.
- input data 크기에 상관없이 output을 도출해야한다.
위의 조건을 모두 만족하는 함수가 "삼각함수" 이다. 삼각함수의 경우 output의 범위가 -1과 1사이로 안정적이며, 주기함수이므로 x값에 상관없이 output 값을 도출해낼 수 있다.
그러나 이러한 주기함수의 단점은 y값이 주기적으로 반복돼, 정보가 겹친다. 이를 해결하기 위해 cos과 sin 함수를 모두 사용하고 각 embedding 차원별로 sin, cos 함수를 번갈아 가며 사용한다.

이렇게 구한 positional embedding vector를 단어 embedding vector와 더해주면 "positional encoding" 작업이 완성된다.
" I love you but not love him" 이라는 문장이라면 앞의 love와 뒤의 love는 일반적인 임베딩만을 거쳤을 때 동일한 값을 가지게 된다. 하지만 Positional Encoding이라는 주기함수에 의한 위치에 따른 임베딩을 거치면 같은 단어일지라도 문장에서 쓰인 위치에 따라 다른 임베딩 값을 갖게 되어 해당 단어의 위치 정보가 성공적으로 모델이 전달된다.
4. Multi-Head Attention 이란?
동일한 Query , Key, Value(= 하나의 단어에 대해서)에 대해서 여러개의 Attention을 동시에 병렬적으로 수행하는 것을 Multi-Head Attention이라고 한다. 여러 버전의 Attention을 수행하기 위해 다수의 선형 변환 행렬 (WQ , WK, WV)을 Multi-Head라고 부르며, 이 Multi-Head에 대해 Attention을 수행하는 것을 Multi-Head Attention이라고 부른다.
🤔 Multi-Head Attention이 필요한 이유 ?
하나의 단어가 여러가지 feature을 가질 수 있으므로 다수의 represenntion을 포함하기 위함이다.

위의 그림을 보자. 예를 들어 making의 경우 more difficult 처럼 "어떻게"에 대한 정보와 2009처럼 "언제"에 대한 정보와 연결될 수 있다. 이러한 경우 , 다양한 representation을 반영하기 위해 Multi-Head Attention을 수행할 수 있다.
multi-head attention을 사용하게 되면 위 그림처럼 각 head는 입력 시퀀스의 서로 다른 부분에 attention을 주기 때문에 모델이 입력 토큰 간의 더 복잡한 관계를 다룰 수 있어 입력 시퀀스를 더 많은 정보로 표현할 수 있다.


이전에는 단 한번의 Attention을 통해 학습시켰으나, Attention을 병렬로 여러 개 사용할 때 더욱 성능이 좋아졌다고 한다. 위의 그림처럼 head의 수 만큼 Attention을 각각 병렬로 나누어 계산하고, 도출된 Attention ouput들은 마지막에 concat을 통해 하나로 합쳐진다. 이렇게 되면 Attention을 한번 사용할 때와 같은 크기의 결과가 도출된다.
예를 들어서 [4X4] 크기의 문장 임베딩 벡터와 [4X8] 의 Query, Key, Value가 있을 때 일반적인 한번에 계산하는 Attention a메커니즘은 [4X4]*[4X8] = [4X8] 의 attention 결과값이 나오게 된다.

반면 Multi-head attention 메커니즘은 head의 수를 4개라고 할 때 각 연산과정이 4분의 1만큼만 필요하다는 이야기이다. 때문에 위에서 [4X8] 이었던 Query , Key ,Value를 4등분하여 [4X2]로 만든다. 이렇게 되면 attention의 결과값은 [4X2] 가 되며, 이 결과값들은 마지막에 concat 시켜주면 [4X8] 이 되어 attention을 한번 사용할 때와 attention 결과값의 크기는 동일하다.
✍️ ReFerence
[1] 환공지능-트랜스포모와 어텐션메커니즘이란 무엇인가? :
https://zrr.kr/cjV0
[2] Attention Networks : A simple way to understand Multi-Head Attention:
https://medium.com/@geetkal67/attention-networks-a-simple-way-to-understand-multi-head-attention-3bc3409c4312
https://zayunsna.github.io/blog/2023-09-05-self_attention/
[3] 코딩 오페라 :
https://codingopera.tistory.com/44
[4] 트랜스포머 파헤치기 :
https://www.blossominkyung.com/deeplearning/transformer-mha
'ML&DL' 카테고리의 다른 글
| [DL] Attention (0) | 2025.01.11 |
|---|---|
| LLM Knowledge Update (0) | 2024.12.12 |
| [DL] Dropout (0) | 2024.06.20 |
| [DL] Data Augmentation (1) | 2024.06.20 |
| [DL] Batch Normalization (1) | 2024.06.19 |