
1. Batch
Batch의 사전적인 의미는 "집단, 무리" 라는 의미입니다. 딥러닝에서 Batch는 전체 데이터를 N개의 묶음으로 나누며, 한 묶음 당 모델의 가중치를 한번씩 업데이트시킵니다.
- 일반적인 gradient descent에서는 gradient를 한번에 업데이트하기 위해 모든 학습 데이터를 사용합니다.
- 즉, 학습 데이터 전부를 넣어서 gradient를 구하고, 그 모든 gradient를 평균내어 한번에 모델 업데이트를 진행합니다.
- 대용량의 데이터를 한번에 처리하지 못하기 때문에 데이터를 Batch 단위로 나눠서 학습하는 방법을 사용합니다.

- SGD(Stochastic Gradient Descent)에서는 Gradient를 한번 업데이트 하기 위해 일부의 데이터만을 사용합니다.
- 한 번 업데이트하는데 B개의 데이터를 사용하였기 때문에, 평균을 낼 때도 B로 나눠줍니다.
2. Internal Covariate Shift
Batch size 만큼 훈련하고 모델을 업데이트 시키는 방법을 MSGD(Mini-Batch Stochastic Gradient Desecent) 라고 합니다.
이렇게 Batch 단위로 학습하게 되면 발생하는 문제점은 바로 Internal Covariate Shift 입니다.
Internal Covariate Shift란?
학습 과정에서 layer별로 입력 데이터의 분포가 달라지는 현상을 말합니다.
예를 들어 Train 데이터의 분포와 Test 데이터의 분포가 다르면 학습이 잘 안되는 것과 같이 학습과정에서 layer별로 입력 데이터의 분포가 달라지면서 모델의 학습을 불안정하게 만들 수 있습니다.
Covariate Shift : 이전 layer의 파라미터 변화로 인해 현재 layer의 입력 분포가 바뀌는 현상
Internal Covariate Shift : layer를 통과할 때마다 Covariate Shift가 발생하면서 입력 데이터의 분포가 변화하는 현상

이 문제를 해결하기 위해 weight를 잘 초기화 해주거나 learning rate를 작게 주어서 변화량을 줄이는 방법이 사용되었습니다. 하지만 weight를 잘 주는 것은 어려운 방법이고 작은 learning rate를 사용하는 방법은 학습이 매우 더디게 진행되어 local minimum에 빠지는 위험도 존재합니다. 따라서 새롭게 제안된 방법이 Batch Normalization입니다.
Hidden layer에서의 변화량이 너무 크지 않으면 학습도 안정하게 될 것이라는 concept 이며, 이는 곧 Batch Normalization의 목표입니다.
즉 ,정리하자면 epoch 마다 input 데이터의 분포가 달라지면 학습 효율이 감소하니, input 데이터들의 분포를 통일시켜 학습을 안정화 시키자!!
3. Batch Noramlization
Batch Noramlization은 학습과정에서 각 배치 단위별로 데이터가 다양한 분포를 가지더라도 각 배치별로 평균과 분산을 이용해 정규화하는 것을 말합니다.
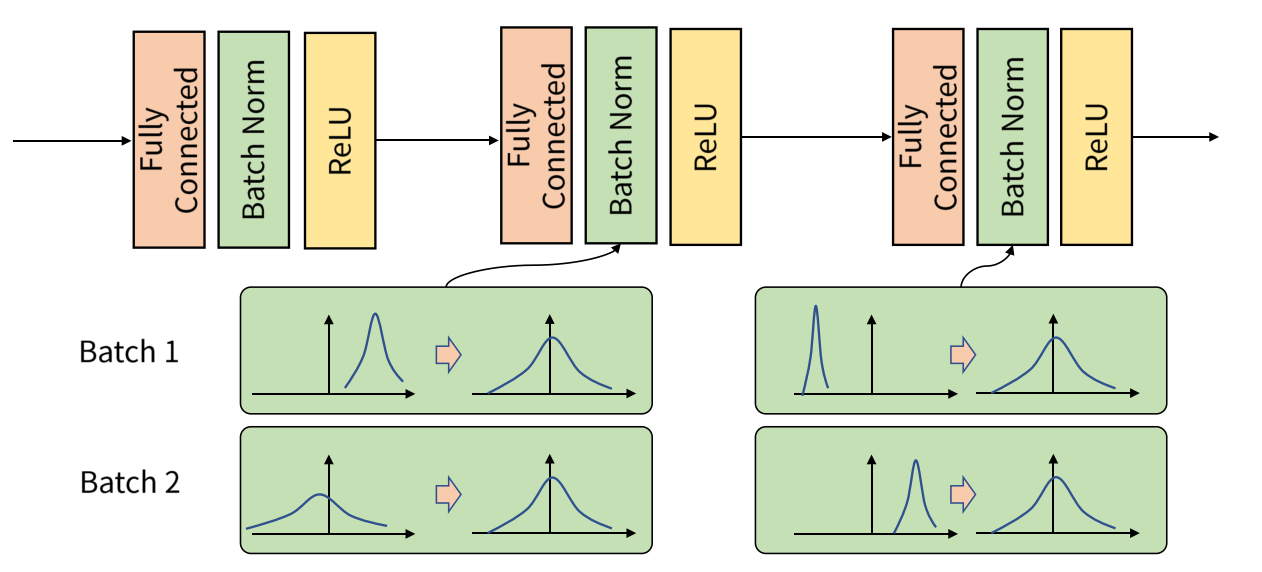
- Batch 단위나 layer에 따라 입력값의 분포가 모두 다르지만, 정규화를 통해 zero mean gaussian 형태로 만듭니다.
- 평균은 0, 표준편차는 1인 분포로 변환할 수 있습니다.
- Activation input이 일정한 분포를 따를 때, 모델이 안정적으로 학습할 수 있습니다.
⭐여기서 Activation Function 의 input으로 무조건 표준 정규분포를 넣어야하는가? 에 대한 대답은 "아니요" 입니다.
- 분포를 일정하게 해주는 건 좋지만, 어느 분포에 맞출것인지는 모델이나 task에 따라 달라진다고 합니다.
- Batch Noramlization은 input의 분포를 0과 1에 맞춰주는 것이 아닌 분포를 일정하게 하는데 목적이 있습니다.
- 효율적인 결과를 내기 위한 최적의 평균과 분산은 학습을 통해 업데이트됩니다. ( 𝛾, 𝛽)
4. 추론 단계의 Batch Noramlization
Batch Normalization은 학습단계와 추론단계에서 다르게 적용되어야 합니다.
학습단계의 Batch Norm

- Batch Norm은 Activation function 앞에 적용됩니다. Batch Norm 을 적용하면 weight의 값이 평균(0) , 분산(1)인 분포로 바뀝니다.
- 𝛾, 𝛽 가 정규화 값에 곱해지고 더해져서 ReLU가 적용되더라도 기존 음수 부분이 모두 0으로 되지 않도록 방지해줍니다.
- 해당 값은 학습을 통해 효율적인 결과를 내기 위한 값으로 찾아가는건 물론입니다!
추론단계의 Batch Norm

- 추론과정에서 BN에 적용할 평균과 분산은 고정값을 사용합니다.
- 그 이유는 학습단계에서 데이터가 배치 단위로 들어오기 때문에 batch의 평균과 분산을 구하는 것은 가능하지만, 테스트 단계에서는 batch 단위로 평균과 분산을 구하기 어렵기 때문입니다.
- 테스트 시 사용할 평균과 분산은 학습과정에서 이동평균(Moving average) 또는 지수평균(Exponential average) 을 통하여 계산합니다.
- 이때 사용되는 𝛾,𝛽 는 학습과정에서 학습한 파라미터 임을 기억해야합니다!
학습단계에서는 Batch 별로 Batch Normalization이 계속 변경되고 업데이트되지만 추론 단계에서는 학습단계에서 이동평균 또는 지수평균에 의하여 고정된 값을 사용합니다.
⭐ 학습과정과 추론 과정의 알고리즘이 다르므로 framework 사용시 , 학습과정과 추론 과정이 다르게 동작하도록 관리를 잘 해줘야합니다. (추론 과정에서는 framework 옵션을 지정하여 평균과 분산을 moving average / variance 를 사용하도록 해야합니다.)
정리하면 Batch Normalization은 Internal Covariate Shift 문제를 개선시키기 위해 고안되었고, 이것은 Activation 에 들어가게 되는 Input 의 Range를 제한시키는 방법으로 문제를 개선했습니다.
5. Batch Noramlization의 단점
우선 배치정규화는 Batch의 크기에 영향을 많이 받습니다.
만일 Batch의 크기가 너무 작으면 잘 작동하지 않습니다. 극단적으로 Batch size가 1이 되면 평균은 샘플 1개의 값이 되고 표준편차는 0이 됩니다. 이렇게 되면 정상적으로 작동하지 못합니다. 또한, sample의 수가 너무 작을 경우 큰 수의 법칙과 중심극한 이론을 만족하지 못하기에 평균과 표준편차가 데이터 전체 분포를 잘 표현하지 못할 수 있습니다.
반대로 Batch의 크기가 너무 커도 잘 작동하지 않습니다. 적절한 크기의 sample은 중심 극한 이론을 통해 적절한 정규분포를 따르게 되지만 굉장히 큰 sample의 경우, multi model인 gussian mixture model 형태가 나타날 수 있습니다. 이와 같은 경우 단순히 평균과 표준편차를 사용하는 것은 정확한 모델링이라고 말할 수 없습니다. 또한 Batch 크기가 너무 크면 병렬 연산하는데 비효율적일 수 있습니다.
이러한 Batch Normalization의 한계를 개선하기 위해 Weight Normalization이나 Layer Normalization 등이 사용되기도 합니다.
🍀 정리하자면
- 딥러닝에서 Layer가 많아질 때 학습이 어려워지는 이유는 weight의 미세한 변화들이 가중되어 쌓이면 Hidden Layer의 깊이가 깊어질수록 그 변화가 누적되기 때문입니다.
- 각 Layer들의 Input feature가 조금씩 변해서 Hidden Layer에서의 Input feature의 변동량이 누적되게 되면 각 layer에서는 입력되는 값이 전혀 다른 유형의 데이터라고 받아들일 수도 있습니다.
- 예를 들어 Train 분포와 Test 분포가 다르면 학습이 안되는 것 처럼 같은 학습 과정 속에서도 각 layer에 전달되는 feature의 분포가 다르게되면 학습하는 데 어려움이 있습니다.
- 이를 해결하기 위해 제안된 방법이 Batch Normalization입니다. 이는 weight에 따른 가중치의 변화를 줄이는 것을 목표로 합니다. (즉, Activation 하기 전 값의 변화를 줄이는 것이 목표)
- weight와 input의 연산 결과를 Batch 단위로 Normalization하여 Activation function의 입력이 일정한 분포를 따르도록 합니다. (scale을줄인다 → 분포의 variance가 작아진다 → 모델학습의 안정화)
✍🏻 참고자료
이어드림스쿨 4기 DS Track 강의
https://arxiv.org/pdf/1502.03167
https://ffighting.net/deep-learning-paper-review/vision-model/batch-normalization/
https://gaussian37.github.io/dl-concept-batchnorm/
https://www.youtube.com/watch?v=TDx8iZHwFtM&list=PLlMkM4tgfjnJhhd4wn5aj8fVTYJwIpWkS
'STUDY > ML&DL' 카테고리의 다른 글
| [DL] Dropout (0) | 2024.06.20 |
|---|---|
| [DL] Data Augmentation (1) | 2024.06.20 |
| [DL] Activation Function , Non-linear Function (0) | 2024.06.18 |
| [DL] CrossEntropy , KL Divergence (0) | 2024.06.14 |
| [CV] Diffusion이란? (1) | 2024.04.26 |