1.Diffusion 모델
Diffusion 모델의 작동방식은 컵에 담긴 물에 잉크를 떨어뜨리는 것으로 비유할 수 있다.
예를 들면, 유리컵에 담긴 물에 잉크를 떨어뜨리면 확산이 일어나 잉크가 물 전체로 퍼지게 된다.
Stable Diffusion에서는 이 현상을 Forward Diffusion이라고 한다.

Diffusion 모델에서는 원본 이미지에 노이즈를 첨가하여 마지막에는 완전한 노이즈가 되도록한다.
이는 잉크가 물 안에서 서서히 퍼지다가 완전히 퍼지게 되는 것과 동일하다.
Revese Diffusion은 이미 물에 완전하게 퍼진 잉크를 다시 돌려 잉크를 떨어뜨린 위치를 맞추는 것과 비슷하다.
이 과정에서 완전한 노이즈에서 노이즈를 한단계씩 제거하면 원본 이미지를 복구한다.
위와 같은 과정이 Diffusion 모델의 전반적인 과정이다.
2. Noise Predictor , U-Net
Reverse Diffusion 과정에서 완전한 노이즈에서 노이지를 제거하면 이미지를 생성한다. 하지만 무작위로 노이즈를 제거한다고 해서 원본 이미지가 복구되거나 새로운 이미지가 생성되지 않는다.
Reverse Diffusion 과정을 성공적으로 이행하기 위해서는 노이즈가 얼마나 추가되었는지 알아야한다.
이 것을 도와주는 것이 Noise Preditor(노이즈 예측기) 라고 하며, 스테이블 디퓨전에서는 U-Net 모델이라고 불린다.
우리는 Forward Diffusion 과정을 수행하며 noise predictor을 훈련한다.

이미지에 노이즈를 하나씩 추가하고 그 결과를 noise predictor에게 알려주며 훈련이 진행된다.
이 과정을 여러번 수행함으로써 noise predictor은 Reverse Diffusion을 성공적으로 수행할 수 있도록 훈련된다.
3.Reverse Diffusion
Revesere Diffusion이 놀라운 것은 물에 완전히 퍼진 잉크를 역추적하여 잉크를 떨어뜨린 위치를 알아내는 것이다.
역추적하는 방법은 잉크가 퍼져나가는 방식을 훈련하여 이를 기반으로 이전 단계를 예측하고 그 과정을 여러번 반복한다.
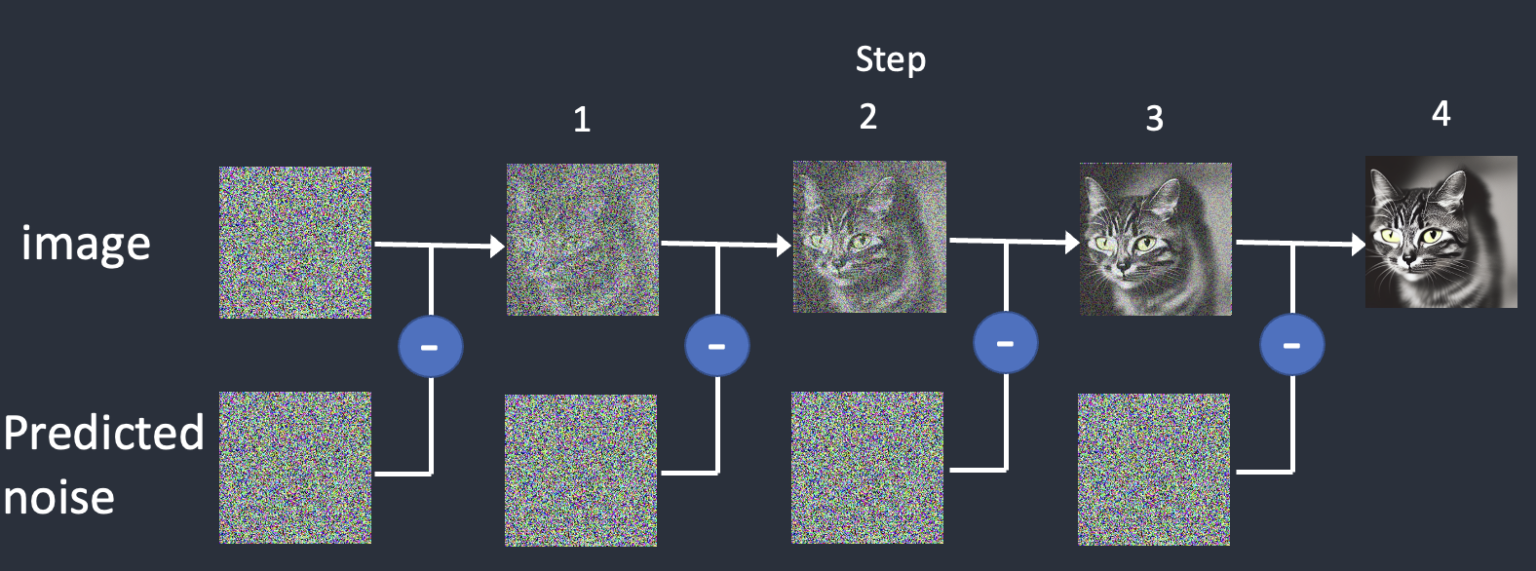
완전한 노이즈에서 노이즈를 추정하고, 추정된 노이즈를 제거한다. 이 과정을 원본 이미지가 복구될때까지 반복한다.
스테이블 디퓨전에서 작동하는 모델은 Diffusion 모델이 아닌 Diffusion모델을 업그레이드 한 Latent Diffusion 모델이다.
4.Latent Diffusion
Latetn Diffusion 모델이란 직역하면 잠재 확산이라는 의미로 Diffusion 과정이 우리가 흔히 알고 있는 픽셀 공간이 아닌 Latent 공간에서 작동하는 방식이다.
Stable Diffusion에서 Diffusion 모델이 아닌 Latent Diffusion 모델을 사용하는 이유는 간단하다.
" 처리해야할 숫자가 훨씬 적다 "
512X512 해상도 이미지 기준 , 픽셀 공간에서는 512X512X3 = 786,432 차원에서 계산하게 되며, Latent 공간에서는 64X64X4 = 16384 차원에서 계산이 가능하다.
즉, Latent Diffusion 모델이 48배 적은 숫자를 처리한다는 장점이 있어 훨씬 빠르게 학습 및 이미지 생성이 가능하다.
이러한 이유로 Stable Diffusion에서는 Latent Diffusion모델을 사용한다.
5.VAE(Variational AutoEncoder)
픽셀 공간에서 Latent 공간으로 이동하기 위해서는 VAE라는 것이 필요하다.
VAE에 대한 역할 설명
- encoder는 어떤 값의 특징을 추출하고 학습하며 decoder은 임의의 값 z(특징에 대한 latent vector)가 주어지면 그 값을 바탕으로 원래 데이터를 복원하는 역할을 한다.
- VAE 그 자체로 하나의 모델이며, pretrained model을 활용한다.
VAE는 인코더, 디코더 두 부분으로 구성된다.
- 인코더는 픽셀공간의 이미지를 Latent 공간으로 압축시키는 역할을 하며
- 디코더는 Latent 공간의 이미지 표현을 픽셀 공간의 이미지로 복원하는 역할을 한다.
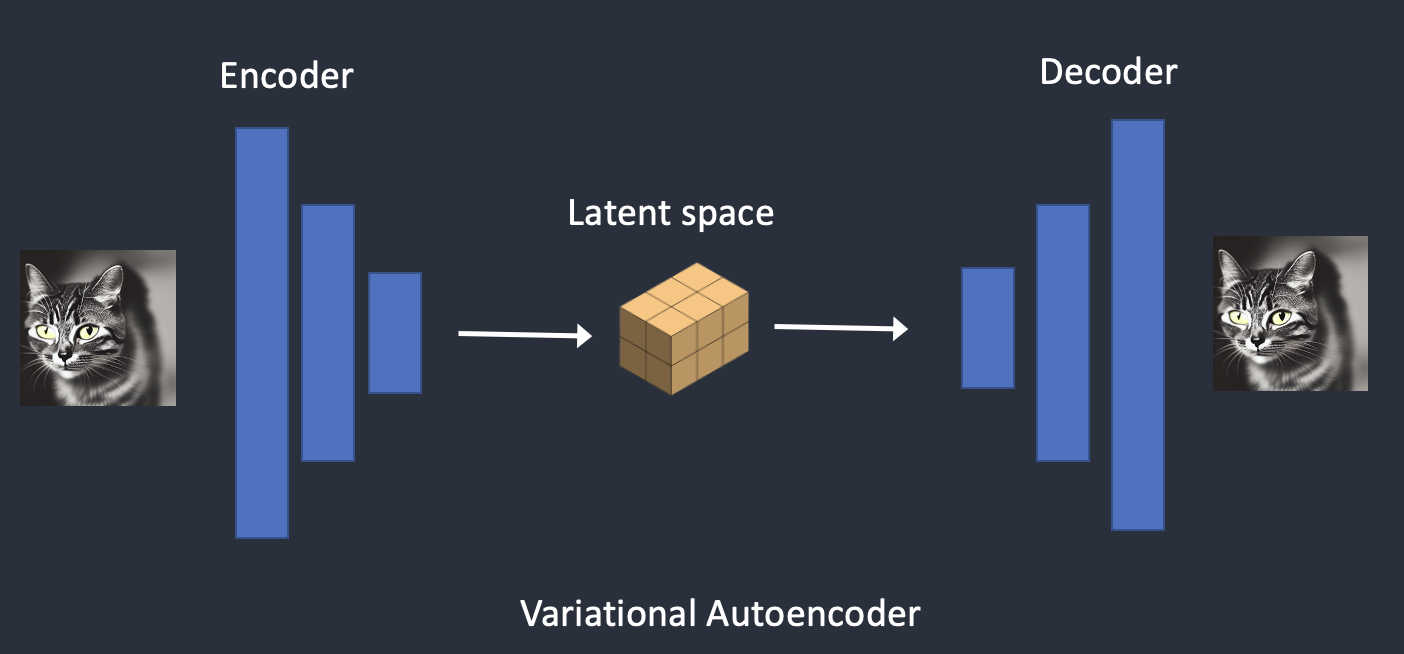
Diffusion 모델의 모든 과정이 Latent Space 에서 이루어진다고 생각하면 좋을 듯 하다.
Latent Diffusion 모델에서는 VAE에 의하여 Encode 되어 latent vector화 된 값을 U-net에 학습해주었기 때문에 U-net에서 복원되어 나온 저해상도의 latent vector을 VAE로 다시 Decode 하여 고해상도의 이미지를 얻을 수 있게 된다.
6.Latent Space → Reverse Diffusion 과정
- Latent 공간에서 임의의 matrix를 생성한다.
- noise predictor는 생성된 임의의 matrix에서 noise를 추정한다.
- 추정된 noise를 제거한다.
- noise를 추정하고, 추정된 noise를 제거하는 과정을 설정해둔 sampling steps 만큼 반복한다.
- VAE 를 통해 noise를 제거한 Latent Space에서의 Matrix를 픽셀 공간의 이미지로 변환한다.
🤔 text prompt 가 Latent Diffusion 모델에서 이미지를 생성할 때 어떻게 관여하는지 알아보자
7.Conditioning
이미지 생성에서 Text Prompt가 관여하기 위해서는 Conditioning이 필요하다.
Conditioning이란?
reverse diffusion 과정에서 noise predictor 가 추정된 noise 혹은 Latent noise를 제거하고, 우리가 원하는 이미지가 될 수 있도록 noise predictor을 조정하는 것을 의미한다.
8.Text Conditioning
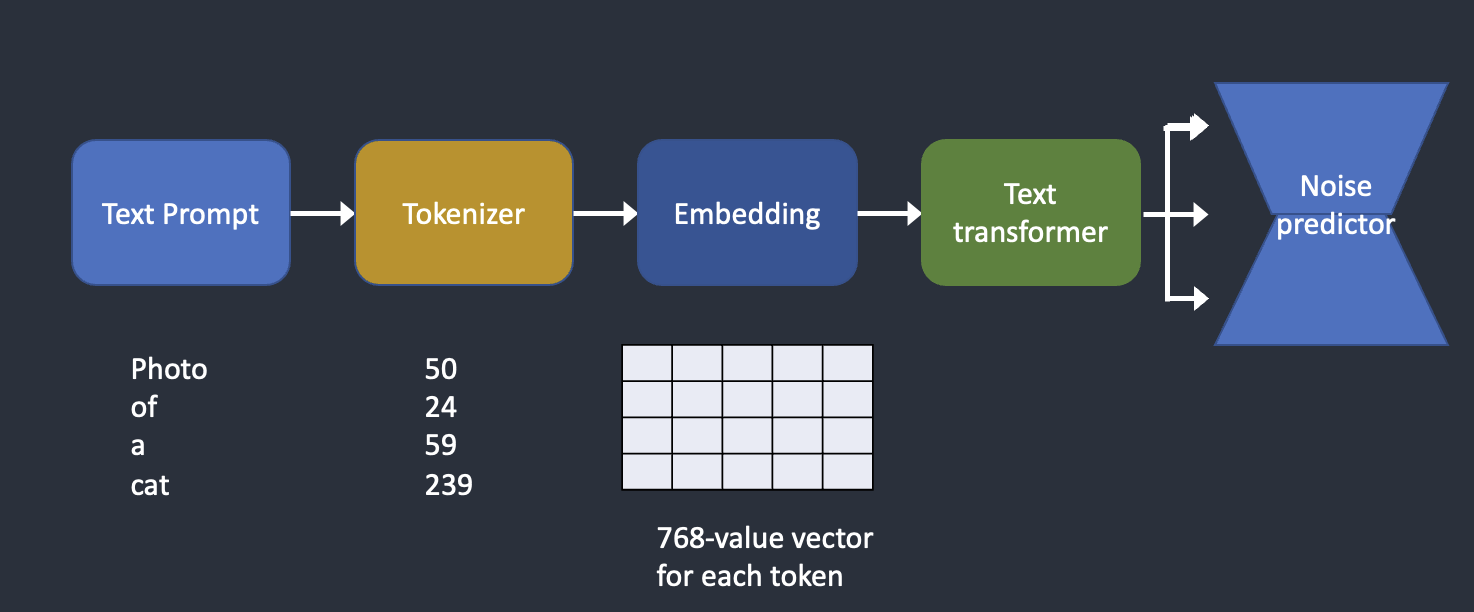
- text prompt 는 tokenizer을 통해 각 token으로 분리된 후 컴퓨터에서 인식할 수 있는 숫자로 변경된다.
- 숫자로 변환된 token은 embedding으로 변환된다.
=> 1,2의 과정을 거쳐야 text가 이미지를 생성하는 Unet에 Conditiong을 할 수 있게 된다. - embedding은 text transformer을 거쳐 noise predictor로 공급된다.
8-1.Tokenizer
tokenizer은 우리가 입력한 텍스트 프롬프트를 컴퓨터가 이해할 수 있는 숫자로 변환해주는 역할을 한다.
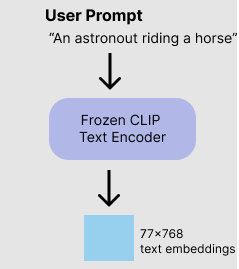
stable diffusion은 Clip tokenizer을 사용한다. Clip은 Open AI 가 개발한 딥러닝 모델로 이미지에 대한 텍스트 설명을 생성하는 모델이다. tokenizer 는 훈련과정에서 본 단어만 토큰화 할 수 있다. 예를 들면, Clip 모델에서 dream 과 beach는 있지만 dreambeach는 없다고 가정해보자.
tokenizer는 dreambeach 라는 prompt를 받게되면 dream과 beach 두개의 토큰으로 분리가 된다 .
(즉, 100% 하나의 단어를 하나의 토큰으로 변환하지 않는다)
webui를 살펴보면 prompt 우측에 최대 토큰 수가 75가 표시되어있으며, 이는 stable diffusion에서 이해할 수 있는 token 수를 이야기 한다.
물론 토큰 수가 75가 넘어가도 프롬프트를 작성할 수 있지만, 프롬프트 이해도가 떨어질 수 있다는 단점이 존재한다.
(따라서 , 되도록 prompt는 75 토큰을 넘어가지 않도록 작성하는 것이 좋다.)
8-2. Embedding
text prompt는 tokenizer에 의해 token으로 변환되고 token은 Embedding이라는 벡터값으로 변환된다.
Embedding은 키워드를 스타일로 변환하기 위해 존재한다. 의미가 비슷한 단어일 수록 임베딩 값은 유사하다.
에를 들면 man, gentleman, guy 등은 비슷한 의미를 가지기 때문에 유사한 임베딩 값을 가지게 된다.
즉, 임베딩은 키워드를 스타일 혹은 개체로 구현할 수 있는 역할을 한다.
8-3. U-Net(Noise Predictor)
임베딩은 text transformer을 통해 한번 더 처리된 후 U-Net으로 공급된다. U-Net은 text prompt 와 이미지가 만나는 공간이다.
Reverse diffusion 과정에서 noise predictor은 추정된 노이즈를 제거하고 이미지에 새로운 것을 제공한다.
text transformer에서 처리된 임베딩은 reverse diffusion 과정에 있는 이미지가 우리가 입력한 text prompt에 따라 생성될 수 있도록 noise predictor을 조정한다.
텍스트 프롬프트가 이미지에 관여하는 과정
- text prompt는 tokenizer을 통해 토큰화 된 후 임베딩으로 변환된다.
- 임베딩은 Text transformer에서 한번 더 처리된 후 U-net에서 이미지와 만난다.
이제 Stable Diffusion의 내부 매커니즘에 대한 모든 것을 알게 되었으니, 이 모델이 어떻게 작동하는지 몇가지 예제를 살펴보자
9. text-to-image
Stable diffusion에 text prompt 를 제공하면 이미지가 반환된다.
단계1. Stable Diffusion은 잠재공간에서 무작위 텐서를 생성한다. 이 텐서는 난수 생성기의 시드를 설정하여 제어할 수 있다.( 시드를 특정 값으로 설정하면 항상 동일한 무작위 텐서가 생성된다)

단계2. U-Net은 잠재 노이즈 이미지와 텍스트 프롬프트를 입력으로 받아 노이즈를 잠재공간에서 예측한다.
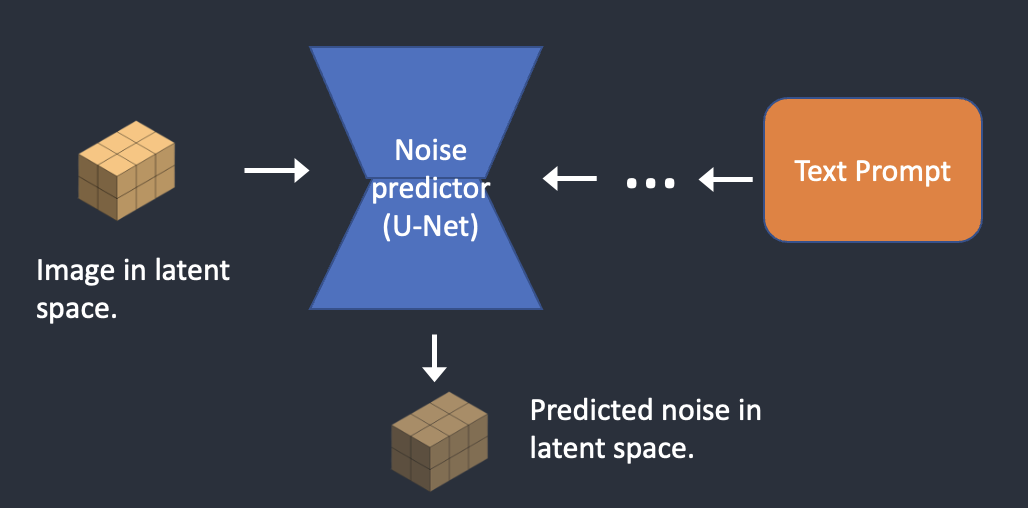
단계3. 잠재 이미지에서 잠재 노이즐르 빼면 새로운 잠재 이미지가 된다.
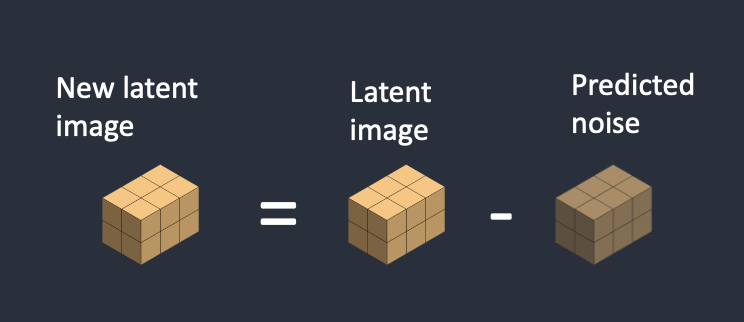
단계4. 이러한 단계를 일정한 샘플링 단계 동안 반복한다. (예를 들면 20회)
단계5. 마지막으로 VAE의 디코더가 잠재 이미지를 픽셀 공간으로 변환한다.
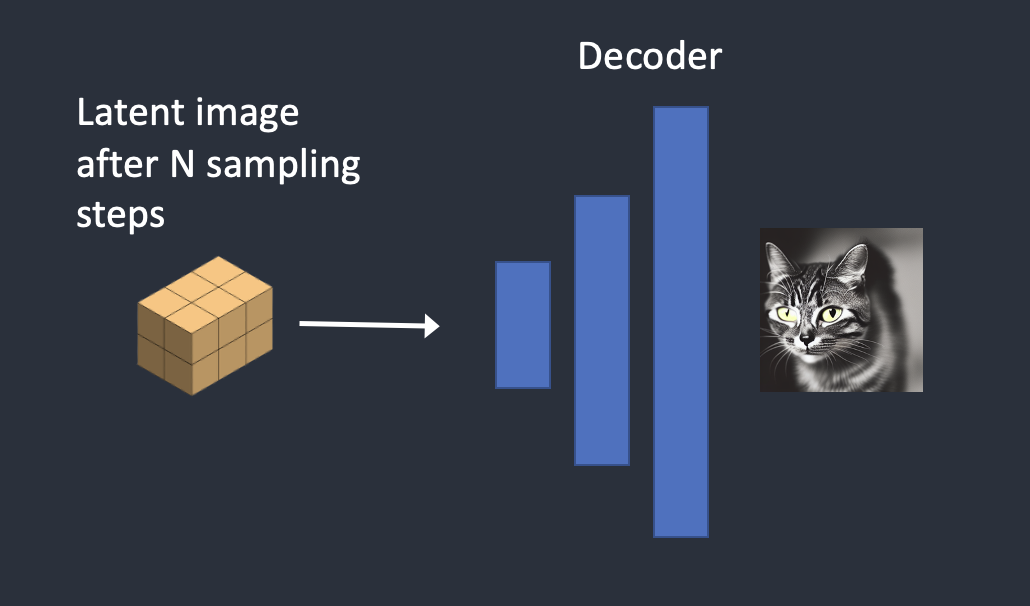
이것이 Stable Diffusion을 실행한 후 얻게되는 이미지이다.
Noise Scheule
이미지는 노이즈에서 깨끗한 이미지로 변환한다. 각 샘플링 단계에서 기대되는 노이즈에 도달하려고 시도한다.
이를 "noise schedule"이라고 한다.
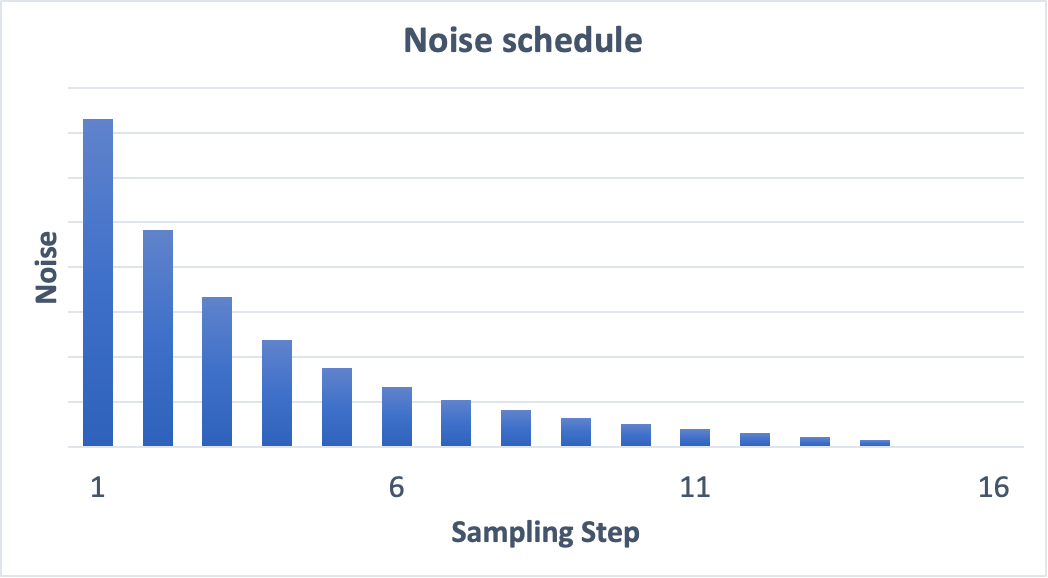
noise schedule은 우리가 정의하는 것이다. 각 단계에서 동일한 양의 노이즈를 빼도록 선택할 수 있는 것인데 위 그림과 같이 처음에는 더 많은 양의 노이즈를 뺄 수 있다.
sampler는 각 단계에서 예상되는 노이즈에 도달하도록 각 단계에서 충분한 양의 노이즈를 뺀다.
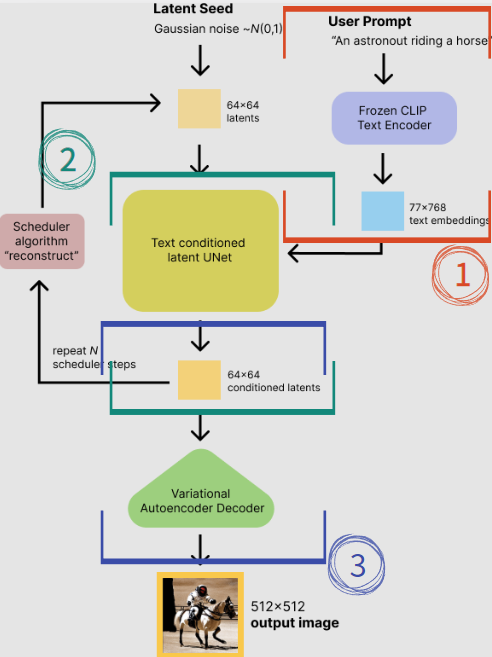
위의 과정을 한번에 나타낸 그림이다. 그림을 보면 더 쉽게 이해할 수 있을 것이다.
SDXL model
SDXL 모델은 v1과 v2로부터 공식적으로 업그레이드 된 모델이다.
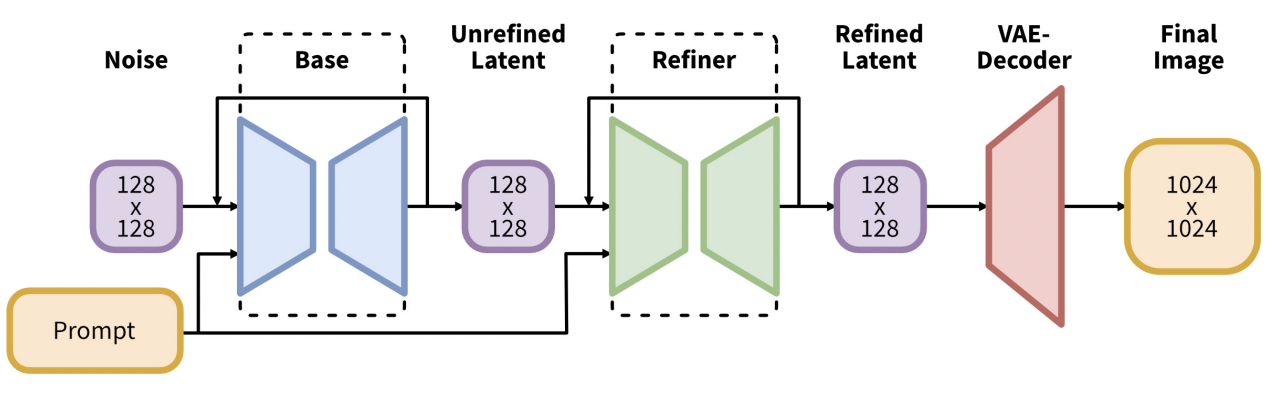
SDXL은 훨씬 더 큰 모델이다. 모델의 총 파라미터수는 66억개인데 비해 v1.5 모델의 경우는 9억 8천만개이다.
SDXL 모델은 실제로 두 개의 모델로 구성되어있다. 먼저 base 모델을 실행한 다음 refiner 모델을 실행한다.
base 모델은 전체적인 구성을 설정하며, refiner 모델은 미세한 세부 사항을 추가한다.
SDXL 기본 모델의 변경사항은 다음과 같다.
- 텍스트 인코더는 가장 큰 OpenClip 모델(ViT-G/14)과 OpenAI의 소유인 CLIP ViT-L을 결합합니다. 이는 SDXL을 쉽게 프롬프팅할 수 있게 만들면서도 강력하고 훈련 가능한 OpenClip을 유지하는 스마트한 선택입니다.
- 새로운 이미지 크기 조건이 도입되어 256×256보다 작은 훈련 이미지를 사용하도록 합니다. 이로 인해 39%의 이미지를 버리지 않고 훈련 데이터를 크게 늘릴 수 있습니다.
- U-Net은 v1.5보다 세 배 더 큽니다.
- 기본 이미지 크기는 1024×1024입니다. 이는 v1.5 모델의 512×512보다 4배 큽니다. (SDXL 모델과 함께 사용할 이미지 크기는 이미지 크기 참조)
✍️ 도움받은 자료
https://ai-designer-allan.tistory.com/entry/
https://stable-diffusion-art.com/how-stable-diffusion-work/
https://pitas.tistory.com/9
'STUDY > ML&DL' 카테고리의 다른 글
| [DL] Dropout (0) | 2024.06.20 |
|---|---|
| [DL] Data Augmentation (1) | 2024.06.20 |
| [DL] Batch Normalization (1) | 2024.06.19 |
| [DL] Activation Function , Non-linear Function (0) | 2024.06.18 |
| [DL] CrossEntropy , KL Divergence (0) | 2024.06.14 |